Structural Noise Removal using Contrastive Learning
Super short summary
The focus was to remove structured noise arising in CT scans due to insufficient sampling of orientations. Used contrastive learning to divide the latent space into two parts: one for the noise and the other for the signal. Given a noisy image, replacing its noise representation in latent space with the noise representation of a clean image led to noise removal from the noisy image.
Overview of the methodolgy
Data
We use the same mathematics involving Radon transforms and fourier transform which is used in reconstructing CT scan volumes from multiple projections to reconstruct a single image from multiple projections. The less the number of projections we take, more is the noise in the reconstructed image.
In short, given a clean image, we have a deterministic function which adds noise to it and the noise is a function of the clean image itself.
Training
Hierarchical Variational autoencoders were used. During training time, we have (a) VAE loss (KL divergence + reconstruction) and (b) contrastive loss (triplet loss). Use of contrastive loss ensures that the latent space is divided into two parts: one for the noise and the other for the signal, as shown in the figure below.

Inference
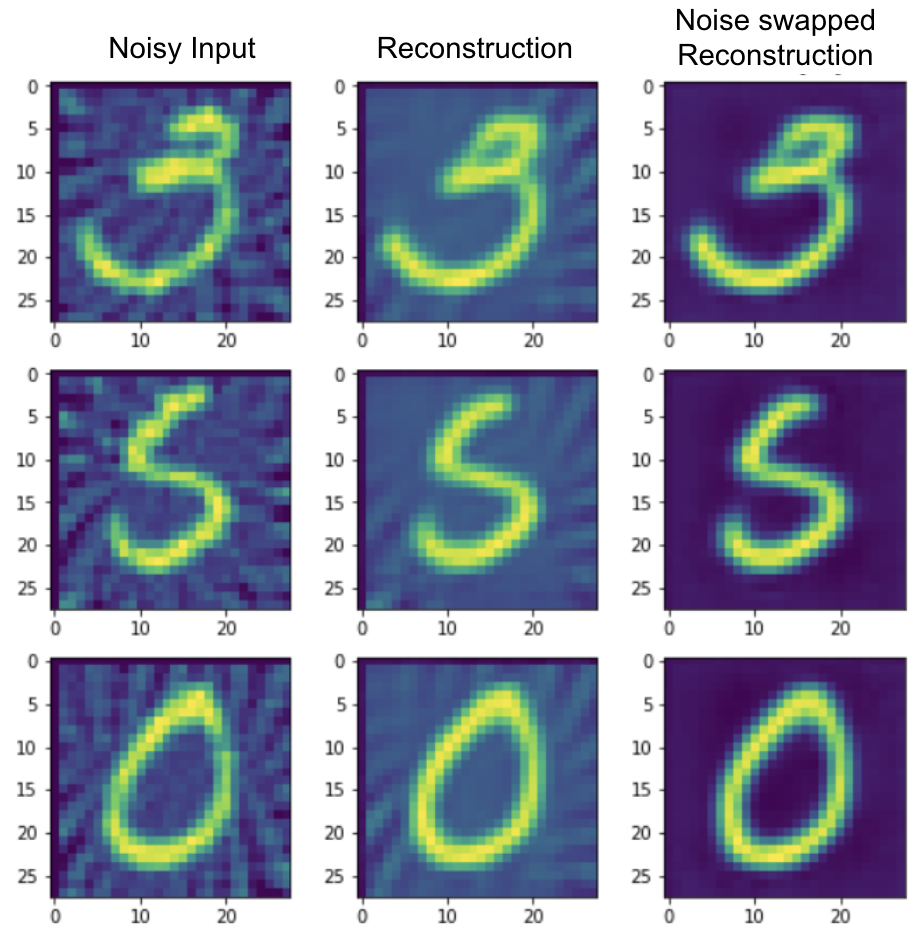
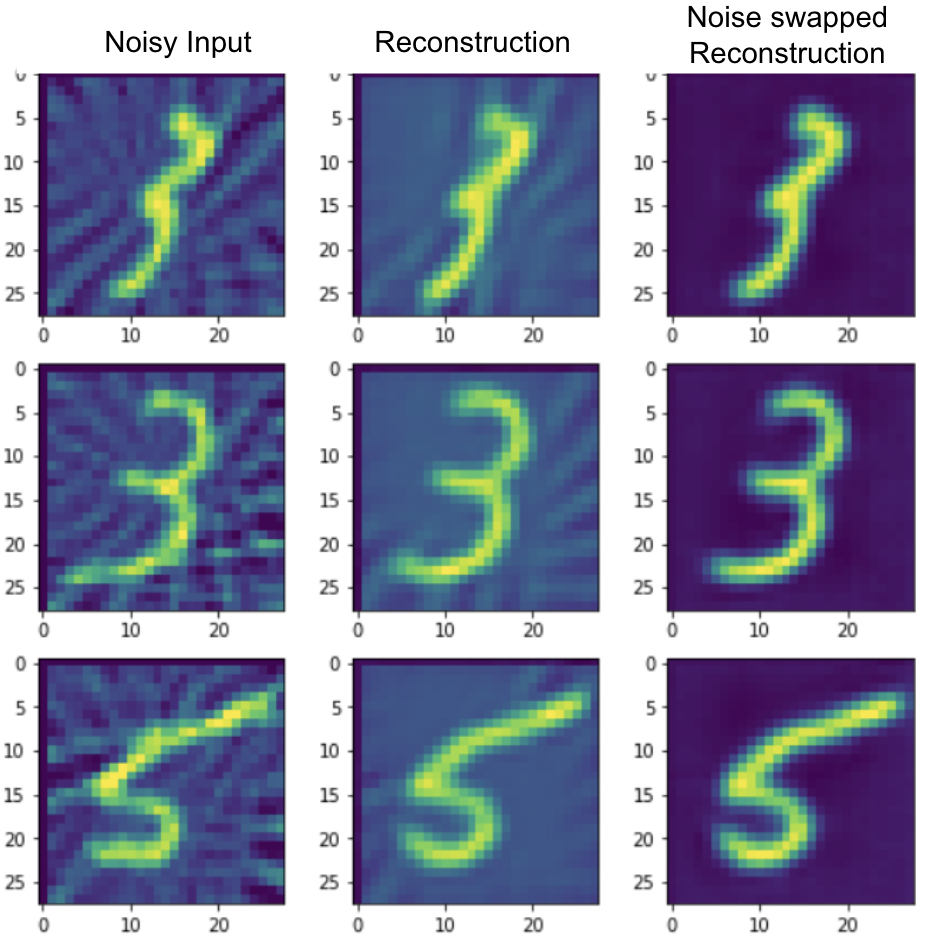
During inference, we have a noisy image. We encode it to get the latent representation. We then swap the noise representation in the latent space with the noise representation of a clean image. We don’t cherrypick the clean image but pick a random one from the dataset. We then decode the new latent representation to get the denoised image. The figure below shows the inference architecture.

Results
We trained our setup on 3 datasets separately: (a) CIFAR-10, (b) notMNIST and (c) Places dataset.
On the notMNIST dataset, we also show the qualitative results of both noise injection and noise removal. First column shows a noisy image and second column shows its reconstruction with the trained Hierarchical VAE. Next two columns shows the same, but for a clean image. In the next two columns, we show the reconstruction after swapping the noise representation in the latent space. To inspect the quality of noise injection, the last column shows the groundtruth version of how noisy version of the clean image (col 3) would look like. It is worth noting that the this structural noise is a function of the clean content. So, the fact that noise injection generates an image which looks a lot like actual noisy image indicates that the network may have implicitly learnt the noise generation process. This is even more impressive when we observe that the network was not explicitly trained to do this. The results are shown below.