
Learning-by-Synthesis for Appearance-based 3D Gaze Estimation
Super Short Introduction
- Paper Link
- Here, they introduce a new dataset for 3D Gaze estimation. Another novelty of the paper is data generation procedure. Using 8 cameras, they are able to reconstruct 3D structure of eye-region using which they generate augmented data by varying the virtual camera and projecting the 3D points onto the virtual camera screen. This yields eye-region with novel head poses. They use regression forest for estimating the gaze.
Brief Overview
Dataset Description
The dataset has 64K images which comprises of 50 subjects, 8 views (head poses) and 160 gaze directions.
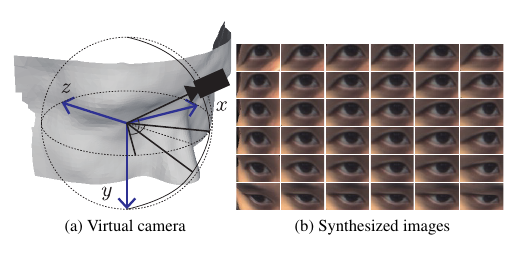
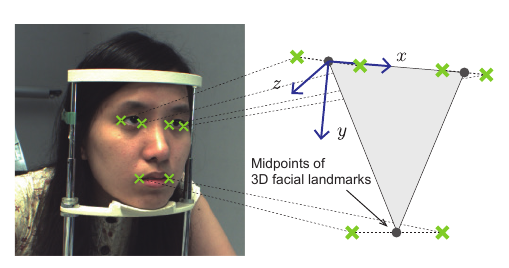
Generation of Synthetic Data
Head pose is defined by the 3D coordinate of eye midpoint and the normal vector of the face plane in the camera coordinate system. They make the original observation that a virtual camera can be introduced such that camera-person distance is fixed to some value. With this configuration, using the two angles in the polar coordinates, the camera position can be determined. They then go on to change the virtual camera position by changing the projection matrix of the camera. They compute the required transformation which needs to be applied to gaze, head pose and the eye image so that all of them are in the new virtual camera coordinate system. This assumes eye region to be planar.
Head Pose based Data Division
They note that head pose determines the range in which the gaze can vary. The actual gaze can be estimated by looking at iris contours. They therefore divide the dataset into overlapping head pose bins and create one model (random regression forest) for each bin.
Model Setup
They use Decision trees to estimate the head pose. As mentioned in previous section, they divide the dataset into overlapping head pose bins and create one model (random regression forest) for each bin. Within each bin, they build Q binary regression trees which trains on a random subset of the data of that bin.