
Super Short Introduction
- Paper Link
- This paper aims to remove artifacts from undersampled MR data for which supervised training of 3D (space + time) residual U-Net architecture is done. The work also analyses the effect of different sampling patterns used in k-space for undersampling. Novelty is achieving 5X speedup in reconstruction process and at the same time achieving better quality reconstructions.
Work Overview
Background
MR data can be represented fully in two ways: as an MR image and as an array of points in continuous K-space. K-space is the fourier transform of the MR image. For fast retrieval of MR data, in practice, less points from K-space are sampled (measured). This is called undersampling. However, the undersampling leads to different kinds of artifacts (also called as aliases) in the MR image. Task here is to remove those artifacts. It has been known from literature that certain sampling techniques lead to non-coherent, noise like artifacts in MR image. CNNs are arguably very good for denoising images and hence they are used in this work as well for denoising the undersampled MR data. So, the assumption is that the artifacts have to be non-coherent for CNNs to work well.
Training Data Generation
Since the data can only be either undersampled MR or sufficiently sampled MR, one needs synthetic data for supervised training. It is so since paired sufficiently sampled and undersampled MR data is needed for supervised training.
- Sufficiently sampled MR data was taken (technical term: bSSFP sine images). They transformed this data so as to mimic real time acquisition. This becomes the ground truth.
- This semi-synthetic real time acquisition data was first converted to K-space. Here, undersampling was performed. Note that paper experiemts with multiple (4) undersampling techniques. The undersampled data was again converted back to MR images.
- Other changes were done to ensure all paired data points had same number of frames temporally (20) and the same spatial dimensions.
Different undersampling strategies
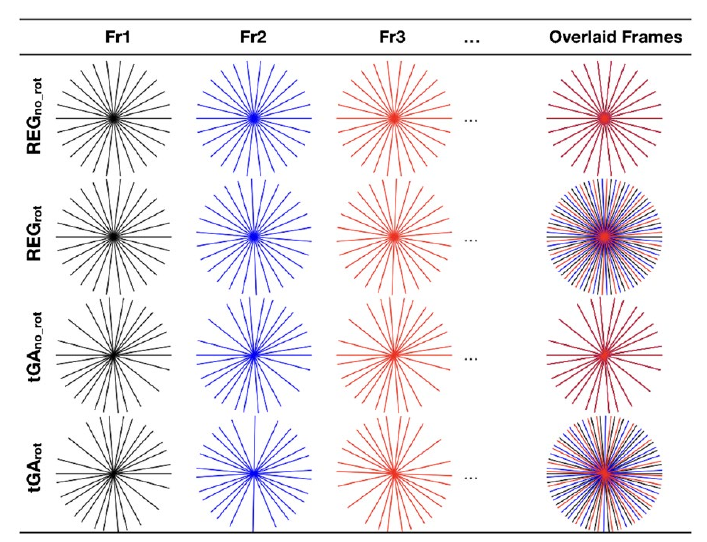
Radial sampling is getting more popular over Cartesian sampling these days. All four strategies tried in this work are from radial sampling (in K-space) which is illustrated in the figure below. In strategies with \(REG_{*}\), there is equal angular spacing between two consequitive radial lines. In strategies with \(*_{rot}\), the radial structure is rotated slightly before doing the sampling for the next frame. \(*_{no-rot}\) means there is no rotation across the temporal dimension.
Broad Inferences
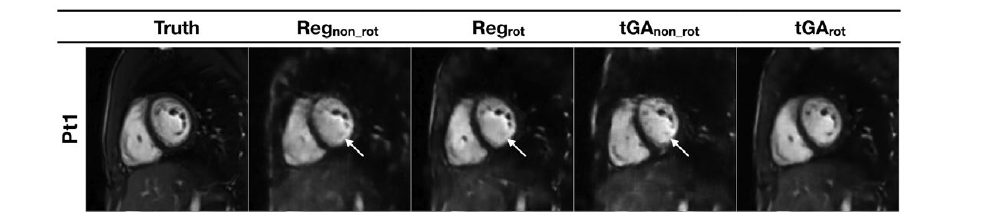
4 networks were trained, each with a different data owing to a different undersampling strategy. It was observed that undersampling technique with rotating trajectories led to better models apparently because the aliases produced by them were in-coherent and noise-like. The reconstruction time had a 5X improvement over contemporary compressed sensing techniques. This model also performed well on actual real time images.
Limitations
The main limitation here is that the training data was created when the patients had to hold their breath. However, in real life (test data), free breathing was allowed. Although the model performed decently on test data as well, this is something which can definitely be improved upon.
Another limititation is regarding the richness of training data. Firstly, MR data is complex valued. Here, magnitude was used and the phase component was ignored. Secondly, MR data is retrieved from multiple coils. Here, a pre-processed form of it was used where multiple-coil data was combined.