
For Computer Vision enthusiasts, we present a novel meta-architecture for image decomposition. The novelty of the approach lies in its use of surrounding spatial context in a GPU efficient way.
From microscopists' perspective, the idea is to use a single fluorophore to stain two different structures (like Actin and Tubulin). The obtained image stack will therefore contain superimposed structures. With our machine learning based approach, the goal is to decompose the superimposed image into two channels, each containing one type of structure.
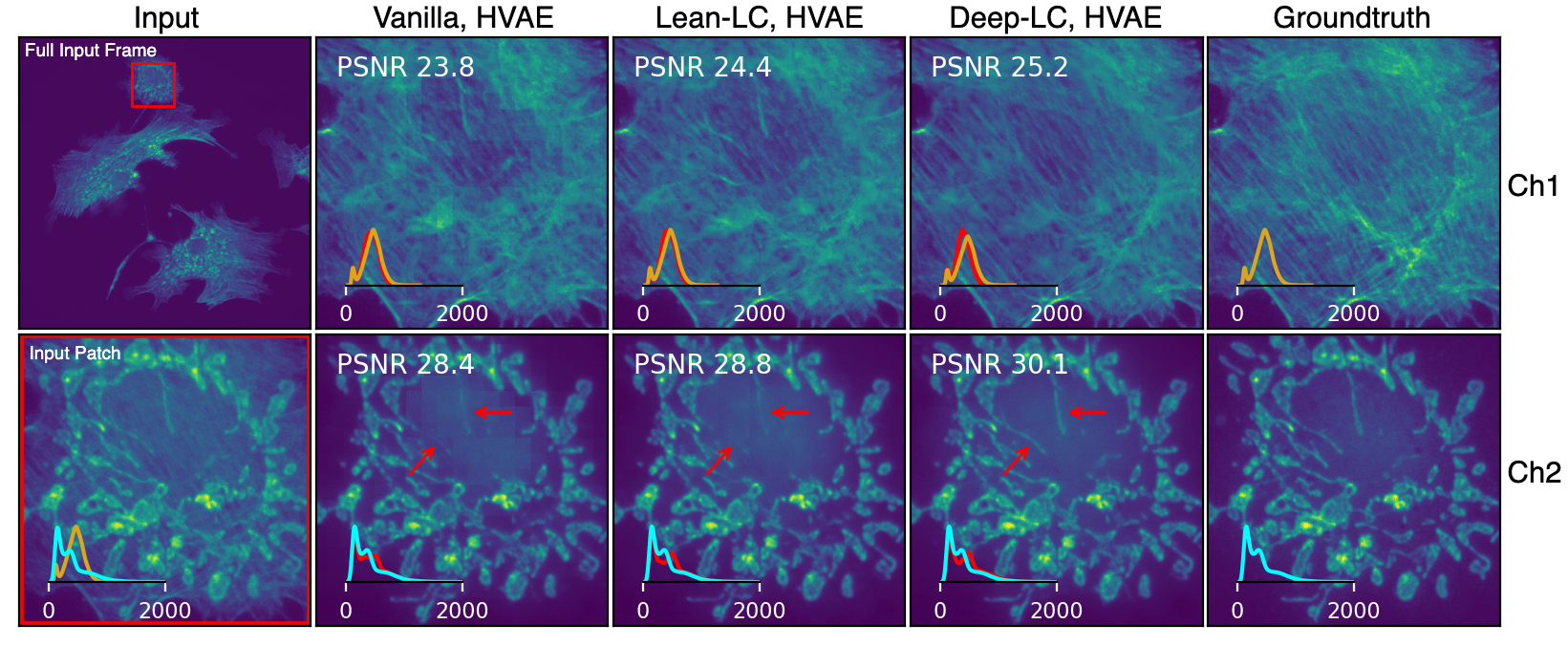
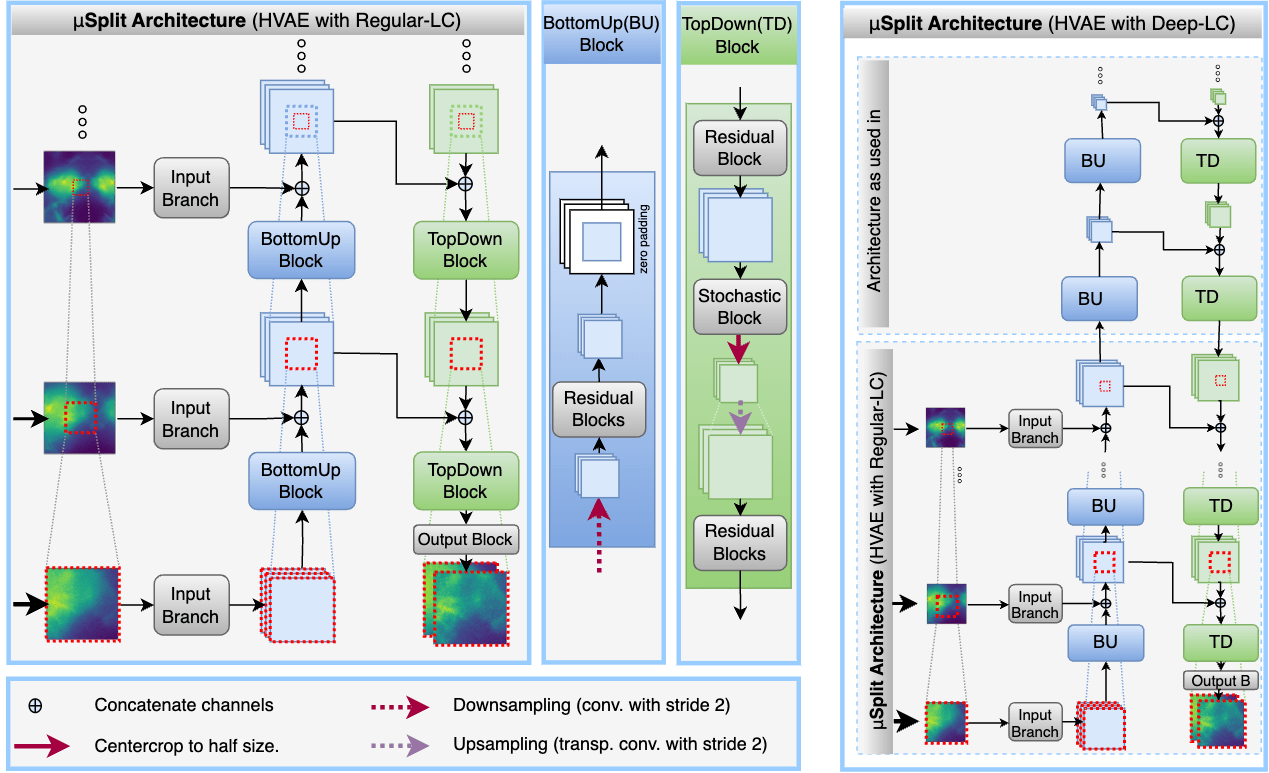
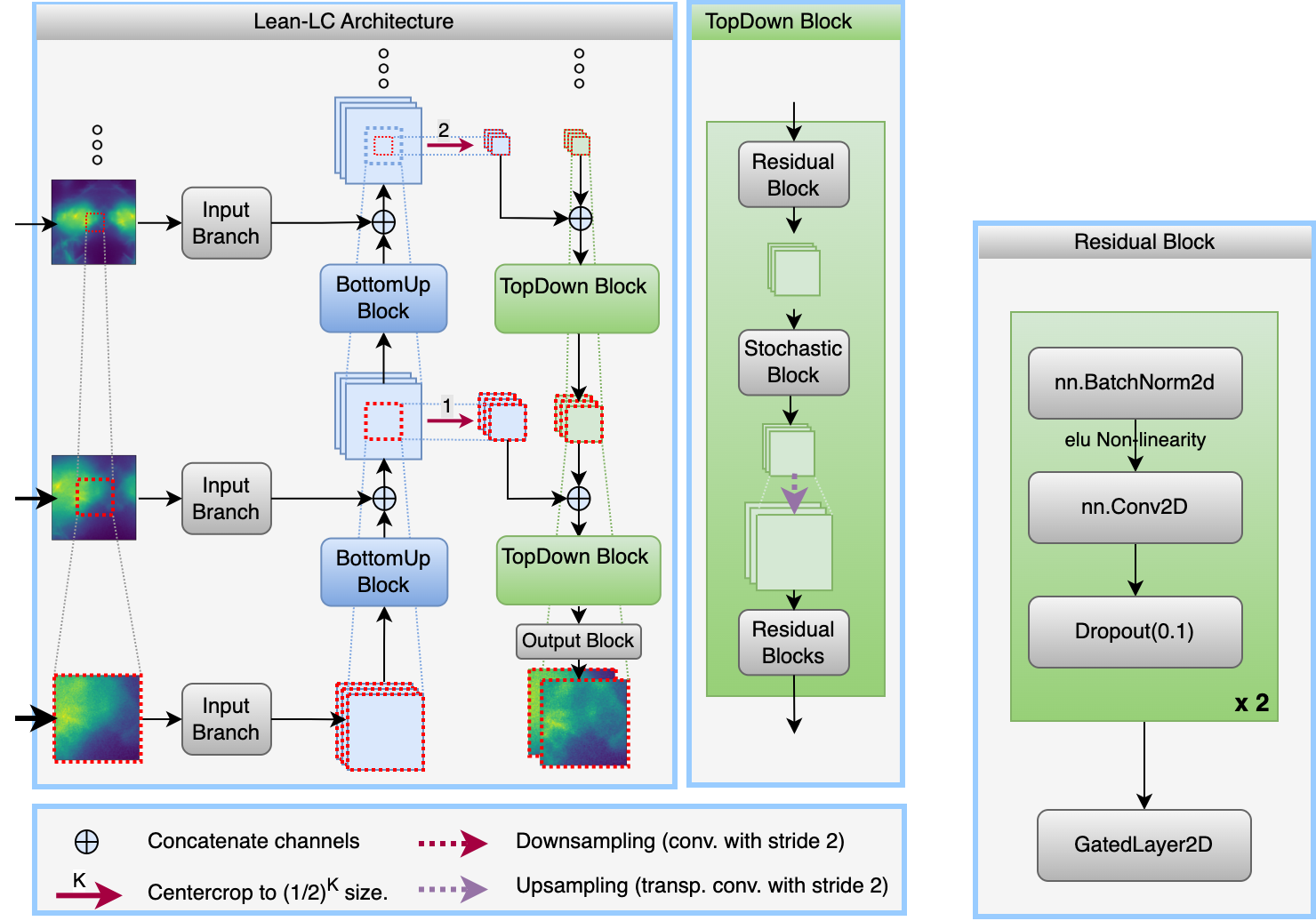
In this work, the task is to decompose input patch into two constituent output patches. A meta-architecture is proposed which is integrated with Hierarchical VAE and UNet variants. The core idea is to use multiple successively lower resolution images alongside the primary input patch. These lower resolution images are centered around the primary input patch and therefore contain the surrounding regions around the primary input patch. The motivation is to provide additional surrounding context to the network in a GPU memory efficient way. The paper also highlights an issue with the prevalent tiling scheme, provides a hypothesis for the issue, and proposes a practical way out.
There are two aspects of this work: (a) The meta architecture µSplit and (b) the tiling strategy.
Our meta architecture, µSplit: Lets start with the intuition behind the meta architecture. To get a good prediction for a pixel, the question we ask is (a) how much surrounding context is needed and (b) at what resolution is it needed. We found that the further away one gets from the pixel in question, it is more often the case that the lower resolution content has sufficient information. Our paper shows this quantitatively. Inline with this empirical observation, our meta architecture makes use of lower and lower resolution images. So, at every hierarchical level, the embedding of the primary input patch, which has undergone downsampling operation, gets merged with the embedding of an equally downsampled (~lower resolution) neighboring patch.
Lets take a concrete example. Given a 64x64 sized patch, the embeddings of the primary patch at successive hierarchical levels will have spatial dimensions of 32X32, 16x16, 8x8 size and so on. At every hierarchical level, we feed 64x64 sized low resolution patch which are created by downsampling the whole input frame two times, four times, eight times and so on and selecting a 64x64 sized patch, which is centered on the primary input patch. Two things are to be noted: At every hierarchical level, 'resolution' level of the primary patch embedding matches the 'resolution' level of downsampled low resolution image which is fed at that hierarchy level. Secondly, these more and more downsampled patches contain lower and lower resolution content of larger and larger regions surrounding the input patch. In this way, a large context is fed to the network in a memory efficient way.
The tiling strategy: For predicting on large input frames, one first predicts on smaller patches and then stitches them together. The tiling strategy is to ensure that the stitching is smooth, i.e, there are no boundary artefacts. In this work, we found that if one uses a much bigger patch size at evaluation time than what was used during training, the performance degrades. This is what happens in the prevalent tiling strategy, which the paper calls 'Outer Padding'. Paper provides a hypothesis as to why this happens and proposes using the same patch size both during evaluation and training, and names it 'Inner Padding'.
@InProceedings{ashesh_2023_ICCV,
author = {Ashesh and
Krull, Alexander and
Di Sante, Moises and
Silvio Pasqualini, Francesco and
Jug, Florian},
title = {uSplit: image decomposition for fluorescence microscopy},
month = {October},
year = {2023},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
}